人工神经网络中最小也是最重要的单元叫神经元。与生物神经系统类似,这些神经元也互相连接并具有强大的处理能力。一般而言,ANNs试图复现真实大脑的行为和过程,这也是为什么他们的结构是基于生物学观察而建模的。人造神经元也是一样的,它的结构令人想起真正的神经元结构。

每个神经元都有输入连接和输出连接。这些连接模拟了大脑中突触的行为。与大脑中突触传递信号的方式相同——信号从一个神经元传递到另一个神经元,这些连接也在人造神经元之间传递信息。每一个连接都有权重,这意味着发送到每个连接的值要乘以这个因子。再次强调,这种模式是从大脑突触得到的启发,权重实际上模拟了生物神经元之间传递的神经递质的数量。所以,如果某个连接重要,那么它将具有比那些不重要的连接更大的权重值。
由于可能有许多值进入一个神经元,每个神经元便有一个所谓的输入函数。通常,连接的输入值都会被加权求和。然后该值被传递给激活函数,激活函数的作用是计算出是否将一些信号发送到该神经元的输出。之前的文章对这方面有更具体的介绍。
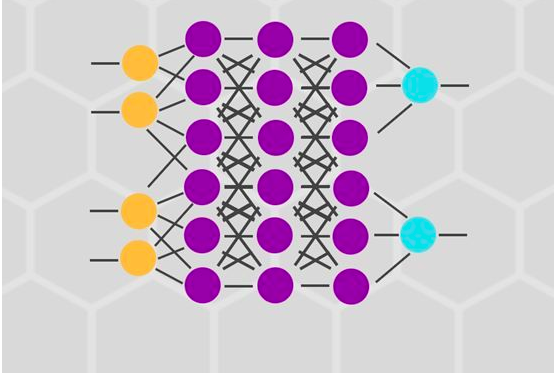
我们可以(并且通常会)在每个ANN中有多层神经元,就如下图所示:
学习
如果我们观察自然界,可以发现能够学习的系统都具有高度适应性。在获取知识之时,这些系统利用外界的输入,修改其已经获得的信息,或者修改其内部结构。这其实就是ANNs的本质——它们适应并修改内部结构从而进行学习。更确切地说,ANNs基于输入和期望的输出来改变连接的权重。
你可能会问:“为什么是权重?” 你仔细观察ANNs的结构,会发现如果我们想修改它们的架构,那么可以修改其内部的一些组件。比如,我们可以在神经元之间创建新连接,或者删除连接,或者添加和删除神经元。我们甚至可以修改输入函数或激活函数。事实证明,修改权重参数是最实用的方法。另外,其他大部分情况可以通过修改权重参数来涵盖。例如,删除连接可以通过将权重设为0来完成(译者注:这里作者的意思类似于dropout机制)。如果我们把一个神经元所有相连的权重都设为0,则相当于删除了该神经元。
训练
在文章的开篇部分,我提到了一个对ANNs非常非常重要的词--- 训练。对于每个ANN而言,这都是一个必要过程,在这期间ANN会熟悉它所需要解决的问题。在实践中,我们会收集一些数据,并基于此创建预测、分类或进行其他处理,这个数据集则被称为训练集。事实上,根据训练期间的行为和训练集的性质,我们可以将学习分为如下几类:
无监督学习 --- 训练集仅包括输入。网络试图识别相似的输入并把他们分类。这种学习受生物学驱动,但并不一定适合所有问题。
强化学习 --- 训练集包括输入,但是在训练期间也会给网络提供额外的信息。 内部机制是一旦网络计算出某个输入的输出,我们就提供信息以表明计算结果是正确的还是错误的,并且可能表明网络错误的性质。
监督学习 --- 训练集包括输入和期望的输出。通过这种方式,网络可以检查它的计算结果和期望输出相不相同,并据此采取适当的行动。
监督学习是最常用的,所以我们来深入探讨一下此话题。基本上,我们会得到一个训练集,包括输入值向量和期望的输出值向量。一旦网络计算出其中一个输入的输出,成本函数便计算误差向量。这个误差表明我们的猜测跟期望的输出有多接近。最常用的成本函数是均方误差函数:
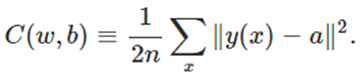
这里,x是训练集中的输入向量,y(x)是人工神经网络产生的输出, a是期望的输出。此外,可以看到这个函数是关于w和b的函数,他们分别代表了权重和偏差(biases)。
现在这个误差被返回神经网络,并且权重被相应地修改。这个过程就是反向传播,它是一个高级的数学算法,人工神经网络通过该算法可以一次调整所有权重。由于这是一个复杂的话题,需要一篇独立的文章介绍,所以建议你阅读这里
(https://rubikscode.net/2018/01/22/backpropagation-algorithm-in-artificial-neural-networks/)需要记住的重点是,通过使用这种算法,ANNs可以快速简单的修改权重。
梯度下降
整个训练的关键是给权重设置正确的值,从而在神经网络中得到期望的输出。这就意味着,我们要使误差向量尽可能小,即找到成本函数的全局最小值。其中一种解决办法是使用微积分。我们可以计算导数,并使用它们找到成本函数的极值所在。然而,这里的成本函数并不是一两个变量的函数,而是网络中所有权重的函数,计算量很快就会变得不可行。这也是为什么我们要使用梯度下降技术。
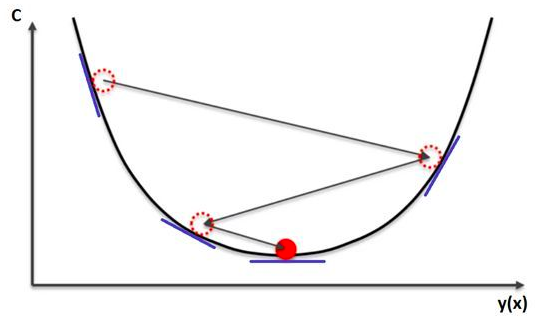
有一个类比可以很好的描述该过程。想象你有一个小球位于如下图所示的山谷中,如果你让小球滚动,它将会从山谷的一边滚到另一边,最终到达谷底。
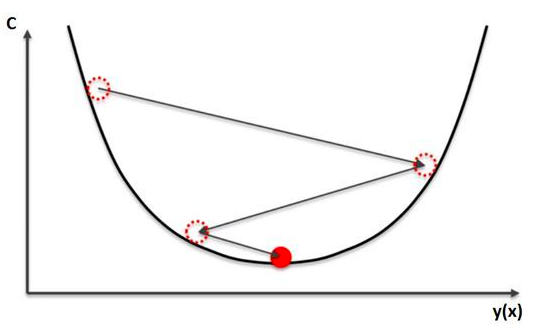
本质上,我们可以如此看待小球的行为:小球从左到右优化它的位置,最终到达谷底,在本例中,底部就是误差函数的最小值。这就是梯度下降算法在做的事情,它从一个位置开始,计算成本函数C的导数和二阶导数得到关于“小球”朝哪滚的信息。每次我们计算导数时,我们都可以得到当前位置山谷边坡的斜率信息,这在下图中用蓝线表示。
当斜率为负(从左到右向下)时,小球应该朝右移动,否则该朝左移动。请注意,小球只是一个类比,我们并不是要准确的模拟一个物理定律。由于我们已经意识到微积分不是最好的方法,所以我们试图用这种替代方法来到达函数的最小值。
简而言之,这个过程是这样的:
将训练集放入神经网络并获得输出。
将输出与期望输出做对比,并使用成本函数计算误差。
基于误差值和使用的成本函数,决定如何改变权重以使误差最小。
重复该过程直到误差值最小。
我刚刚所解释的还有另外一个名字---- 批次梯度下降(Batch Gradient Descent)。这是因为我们把整个训练集放在网络中,然后修改权重。这种方法的问题是,我们可能到达误差函数的一个局部最小值,而不是全局最小值。这也是神经网络中最大的难题之一,不过有多种方式可以解决它。
然而,避免陷入局部最小值陷阱的常用方法是处理完训练集中的一个输入之后就修改权重。当训练集中的所有输入都处理完了,一个epoch也就完成了。为了得到最好的结果,有必要进行多个epochs。这个过程被称为随机梯度下降(Stochastical Gradient Descent)。而且,通过这样做,我们最小化了另一个问题出现的概率 ---- 过拟合。过拟合是指神经网络在训练集上表现良好,而在未知的真实数据上不好。当权重被设置为仅仅解决训练集中的特定问题时,会发生这种情况。
总结
现在,我们总结一下:
在神经网络中随机初始化权重
我们将第一组输入值发送给神经网络,使其传播通过网络并得到输出值。
我们将输出值和期望的输出值进行比较,并使用成本函数计算误差。
我们将误差传播回网络,并根据这些信息设置权重。
对于训练集中的每个输入值,重复2至4的步骤。
当整个训练集都发送给了神经网络,我们就完成了一个epoch, 之后重复多次epochs。
所以,这只是神经网络如何学习的一个简化表示。我没有提到的是,在实践中,训练集被分成两部分,第二部分用于验证网络。
郑重声明:本文版权归原作者所有,转载文章仅为传播更多信息之目的,如作者信息标记有误,请第一时间联系我们修改或删除,多谢。