1951 年,“人工智能之父”Marvin Minsky 借鉴了巴甫洛夫对动物行为的观察结果,开始尝试设计最早的智能机器和神经网络模拟原型。基于动物学习过程中对奖励和惩罚的反应,他创造了一台可以通过不断学习来解决迷宫问题的计算机。
虽然神经科学家当时还没有弄清楚大脑这种学习机制的原理,但 Minsky 仍然能够在一定程度上模仿和复制这种行为,推动了人工智能(AI)的发展。
如今在计算机科学领域,这种机制就是我们熟知的强化学习技术。随着强化学习的不断完善,它反过来可以帮助神经科学家们更深入地了解动物大脑的这种机制,促进了两个领域之间良性循环发展。
《自然》杂志上发表的一篇最新论文中,DeepMind 借鉴了研究强化学习技术得出的经验,提出了一套关于我们大脑内奖励机制的新理论。该假设初步得到了实验结果支持,不仅增进了我们对心理健康和行动动机的理解,还足以证明 AI 研究正朝着通用人工智能技术的方向迈进。
就像开头所说,强化学习算法的内在逻辑建立在巴甫洛夫对动物的实验结果上:仅通过给予积极和消极反馈,就可以教会动物完成复杂而陌生的任务。
对于算法来说,它在学习之初会随机预测哪个行动可能会带来奖励,在采取相应行动后观察实际回报,并且根据误差来调整其预测方式。在最理想的情况下,经过数百万次以上的尝试,该算法的预测误差会收敛至零,这时它就能准确地知道采取哪些行动可以带来最大回报,从而顺利完成任务。
早在 20 世纪 90 年代,受到强化学习算法启发的研究就已经证明,动物大脑中奖励系统的运作方式几乎与这套机制相同。当人或动物将要执行某项行动时,大脑中掌管奖励机制的多巴胺神经元就会计算预期回报。一旦收到了实际奖励,它们便会释放出与预测误差成正比的多巴胺。
如果实际奖励高于预期,就会触发强烈的多巴胺分泌,令人倍感愉悦,而低于预期的回报则会抑制它的产生。换句话说,多巴胺可以被视为是一种校正信号,告诉神经元调整其预测模式,直到它们收敛到符合现实为止。
这种现象称为奖励预测误差(reward prediction error),其工作原理就类似于强化学习算法。
DeepMind 的新论文建立在自然学习机制和人工学习机制之间的紧密联系上。2017 年,其研究人员曾推出了一种改进型强化学习算法,名为分布式强化学习(Distributional RL),在很多任务上的表现令人印象深刻。
他们现在认为,这种算法还可以为多巴胺神经元在大脑中的工作机制提供更准确的解释。

图 | 当未来的结果不确定时,奖励可以被视为一种概率分布:绿色代表好的可能,红色代表坏的可能。经过训练的算法可以掌握这种概率分布模式。(来源:DeepMind)
具体来说,改进的新算法改变了预测奖励的方式。旧方法将奖励估算为一个 “等于平均预期结果” 的整数,而新方法更准确地将其以分布的形式表示出来。这有点类似于赌博或者抽奖的游戏机制,虽然输赢和获胜概率有平均预期值,比如在氪金游戏中常见的抽奖概率 x%,但真实情况却是呈分布状态的,几乎不可能抽 100 次就一定会中 x 次。
采用分布形式的新算法由此引出了一个新的假设:大脑中的多巴胺神经元是否也以类似的分布方式预测奖励呢?
为了验证这一理论,DeepMind 与哈佛大学的一个小组合作,观察了小鼠大脑中多巴胺神经元的活动模式。
他们给一些小鼠安排了任务,然后根据掷骰子结果奖励它们。在整个过程中,研究人员会测量小鼠多巴胺神经元的放电情况,即信号发送情况。他们发现每个神经元释放多巴胺的程度不同。这意味着它们对同一项任务给出了不同的预测结果。
有些神经元会过于“乐观”,预测奖励比实际获得的更高,但另一些则更为“悲观”,会低估实际奖励。研究人员随后绘制出了预测结果的分布图,发现它跟实际奖励的分布图非常相似。这些数据提供了令人信服的证据,表明大脑确实使用了分布奖励预测来增强其学习算法。
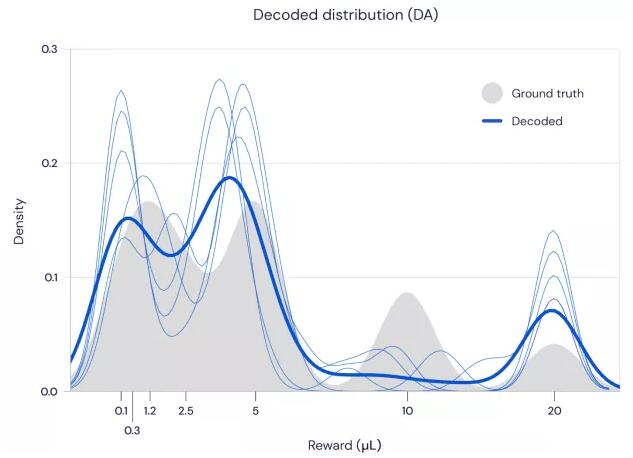
图 | 神经元预测奖励(蓝色)和实际奖励(灰色)呈现出相似的分布规律(来源:DeepMind)
未参与研究的多巴胺神经元行为研究先驱 Wolfram Schultz 在电子邮件中表示,“这是对基于奖励预测误差的多巴胺编码机制的很好扩展。最令人惊讶的是,这种非常简单的多巴胺反应遵循了基本生物学的直观学习过程,而且已经成为了 AI 的组成部分。”
这项研究对 AI 和神经科学都有深刻影响。
首先,它验证了分布强化学习是通往更高级 AI 功能的有效方法,很有希望。DeepMind 神经科学研究主管,论文的主要作者之一 Matt Botvinick 在新闻发布会上说:“如果大脑(选择)遵循了一种模式,那它可能是个好想法。它告诉我们,这是一种可以在现实世界中扩展的计算技术,也会适合其他计算过程。”
其次,该研究可以对神经科学中有关大脑奖励系统的经典理论提供重要更新,从而增进我们对行为动机和心理健康等研究课题的了解。例如,多巴胺神经元会倾向于 “悲观” 和“乐观”意味着什么?如果大脑选择性地只听其中一个,会导致化学物质失衡,甚至导致抑郁吗?
从根本上讲,后续研究会为分析大脑活动提供新的视角,进一步解码大脑的活动机制或许会揭示更多的大脑未解之谜,有望深入挖掘是什么创造了人类的智力。
郑重声明:本文版权归原作者所有,转载文章仅为传播更多信息之目的,如作者信息标记有误,请第一时间联系我们修改或删除,多谢。
